

Overview
EkaCare’s Lab Report Parsing solution leverages its customised vision-LLM to accurately extract structured datasuch as test names, results, units, and reference ranges. Designed specifically for the Indian healthcare ecosystem our solution offers high level of accuracy and doesn’t involve human in a loop.
This service offers:
- Extraction of test name, result, unit, reference ranges, panel and specimen
- Linking of test name to LOINC identifiers
- Linking of unit to UCUM identifiers
- Interpretation of test results
- Output as HL7 FHIR document
- Ability to work with PDFs as well as scanned / clicked images of lab reports
We currently handle LOINC linking for 1400+ lab investigations that cover the majority of commonly performed lab investigations in India. List of LOINC linkable tests
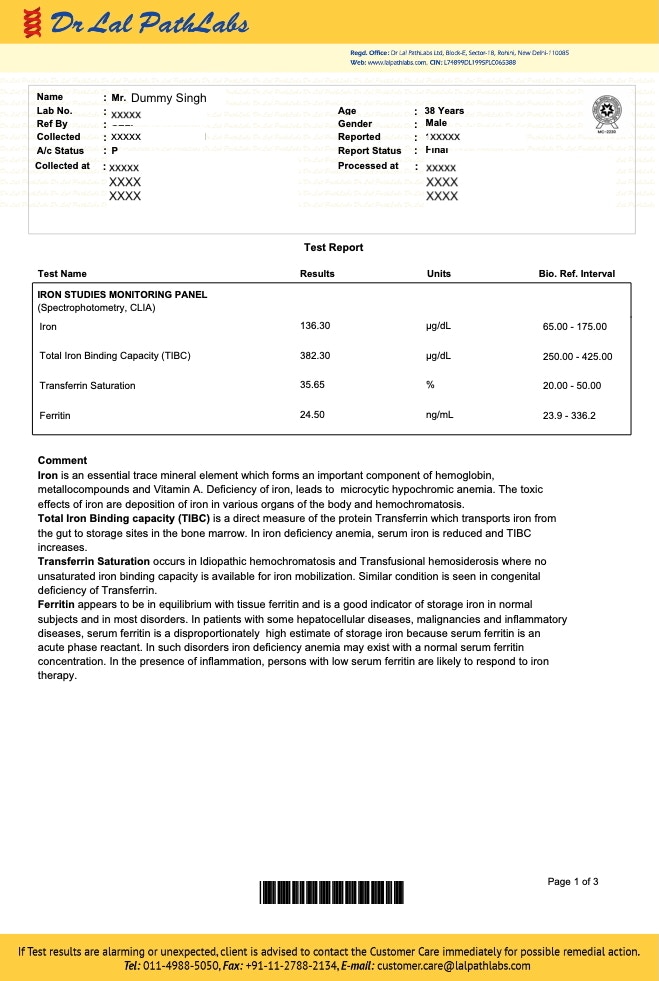
Use Cases
1. HealthCare providers
- Better clinical decision making leveraging longitudinal view of the diagnostic results results
- Enriched medical records enabled by seemless copy of lab outcomes to prescription
2. Personal Health Record (PHR)
- Comprehensive health view based on lab investigations done over years
- Improved awareness and management of health biomarkers
3. Health Insurance Companies
- Streamlining the processing of lab reports submitted during insurance claims.
- Automate fraud detection by validating extracted diagnostic data.
Technology Deep-Dive
Our lab report parsing technology is powered by or custom Large Language Models (LLMs), specifically trained on millions of anonymized medical documents. These documents span diverse formats and contexts, with a particular focus on the Indian healthcare ecosystem. Our rigorous training and fine-tuning process ensures exceptional accuracy while minimizing common pitfalls like hallucinations that often impact other SOTA LLMs.The result is a highly reliable system, as demonstrated in the benchmarks provided in the subsequent section. Our process consists of two core steps:
1. Medical Information Extraction:
Extracting structured medical information from unstructured or pseudo-structured PDFs or images. This includes test names, results, units, ranges, panel names, specimen and method.2. Medical Entity Linking:
Assigning identifiers to the extracted medical concepts. We use LOINC identifiers for lab tests and UCUM identifiers for units. This is what enables interoperability and interpretability of this rich diagnostic data.Evaluation and Benchmarks
Our benchmark experiments with evaluation dataset comprising thousands of documents showcase Eka’s superior performance in terms of accuracy compared to other SOTA models. NOTE this evaluation dataset contains both PDF and clicked images.
A deeper view on results of these experiments are summarised below.
Spotlight
- Lab-Ready and Prescription-Perfect: Eka Care’s Small LLMs vs. Industry Giants
- Extracting Structured Information from Lab Reports: Challenges and Learnings
Try Out
Experience the power of EkaCare’s Lab Report Parsing with our developer-friendly API.- Visit our API Documentation to get started.
- Upload a sample lab report and see our technology in action.
- Contact us for a custom demo tailored to your use case.